引言
嵌入式项目里,线程间通信是绕不开的问题。传感器线程读到数据,UI 线程要更新显示,网络线程要上报——它们之间怎么传消息?
最直接的做法是让模块互相持有对方的指针或队列句柄,但代价是强耦合:改一个模块,另一个也要跟着改。
embedmq 是我写的一个零依赖 C11 库,把线程间消息分发压缩成三个函数:create、register、post。本文从源码层面拆解它的每一个设计决策。

一、传统做法的痛点
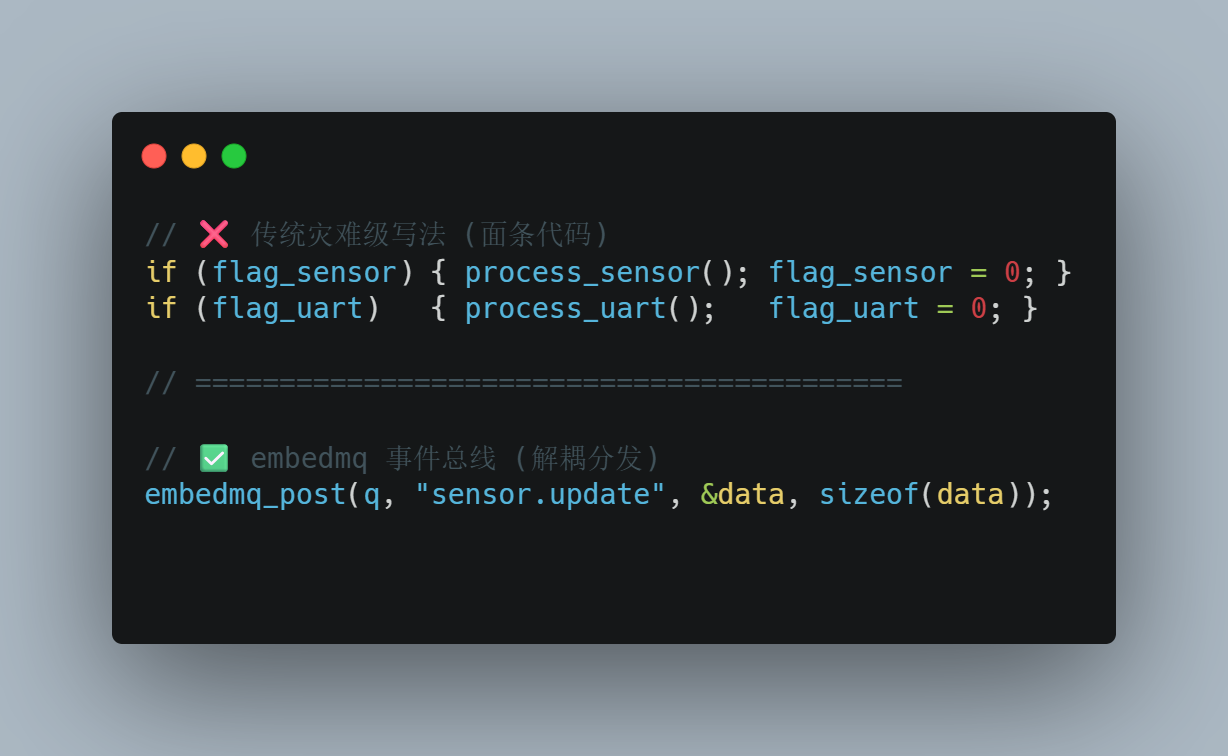
裸机:flag 泛滥
1
2
3
4
5
6
7
8
9
10
| volatile bool g_uart_ready = false;
volatile bool g_sensor_ready = false;
void main(void) {
while (1) {
if (g_uart_ready) { process_uart(); g_uart_ready = false; }
if (g_sensor_ready) { update_display(); g_sensor_ready = false; }
}
}
|
功能少时还好,一旦 flag 超过十几个,main.c 就变成了垃圾桶。增删任何功能都要修改主循环。
RTOS:Queue 句柄散落各处
1
2
3
4
5
6
7
8
| void SensorTask(void *p) {
sensor_data_t data;
while (1) {
ReadSensor(&data);
xQueueSend(ui_queue, &data, 0);
xQueueSend(log_queue, &data, 0);
}
}
|
生产者和消费者互相知道对方的存在,增加一个消费者就要修改生产者代码,违反开闭原则。
Linux:重复造轮子
1
2
3
4
| pthread_mutex_lock(&data_mutex);
shared_data = new_value;
pthread_cond_signal(&data_cond);
pthread_mutex_unlock(&data_mutex);
|
每个项目都在重写同样的 mutex + 条件变量组合,且容易死锁。
二、embedmq 的解法:发布-订阅解耦
1
2
3
4
5
|
embedmq_post(q, "sensor.temp", &data, sizeof(data));
embedmq_register(q, "sensor.temp", on_temp, NULL);
|
两边通过事件名字符串约定,库负责中间的一切:哈希、队列、线程、派发。
需要明确的一点:每个事件名只能绑定一个 handler。embedmq 解决的是模块解耦,不是一对多广播。如果需要多个模块响应同一个事件,可以用不同的名字:
1
2
| embedmq_register(q, "sensor.temp.ui", on_ui, NULL);
embedmq_register(q, "sensor.temp.log", on_log, NULL);
|
一个完整的三线程例子
用 embedmq 重写开头的问题场景,感受一下解耦的效果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
| #include "embedmq.h"
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
typedef struct { float celsius; int humidity; } sensor_data_t;
typedef struct { int rssi; char ssid[32]; } wifi_info_t;
static embedmq_t *g_bus;
static void on_sensor(const void *data, size_t size, void *ctx)
{
const sensor_data_t *d = data;
printf("[UI] 温度: %.1f°C 湿度: %d%%\n", d->celsius, d->humidity);
}
static void on_wifi_connected(const void *data, size_t size, void *ctx)
{
const wifi_info_t *w = data;
printf("[UI] WiFi 已连接: %s (RSSI=%d)\n", w->ssid, w->rssi);
}
static void *sensor_thread(void *arg)
{
sensor_data_t d = {0};
while (1) {
d.celsius = 25.0f + (rand() % 50) * 0.1f;
d.humidity = 55 + rand() % 20;
embedmq_post(g_bus, "sensor.update", &d, sizeof(d));
usleep(100000);
}
return NULL;
}
static void *network_thread(void *arg)
{
wifi_info_t w = { .rssi = -55 };
snprintf(w.ssid, sizeof(w.ssid), "HomeNetwork");
embedmq_post(g_bus, "wifi.connected", &w, sizeof(w));
return NULL;
}
int main(void)
{
g_bus = embedmq_create(NULL);
embedmq_register(g_bus, "sensor.update", on_sensor, NULL);
embedmq_register(g_bus, "wifi.connected", on_wifi_connected, NULL);
pthread_t t1, t2;
pthread_create(&t1, NULL, sensor_thread, NULL);
pthread_create(&t2, NULL, network_thread, NULL);
sleep(1);
embedmq_destroy(g_bus);
}
|
sensor_thread 和 network_thread 里没有任何 UI 相关的引用,以后换掉 UI 层什么都不用改。
三、核心机制深度拆解
3.1 一条消息的完整旅程
这是理解整个库最重要的部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| 你的线程(生产者) 库内部(消费者线程)
│ │
│ embedmq_post("sensor.temp", &d, n) │
│ │
▼ │
1. FNV-1a hash("sensor.temp") → UUID │
│ │
▼ │
2. mutex 加锁 │
│ │
▼ │
3. 写入 ring buffer │
[UUID 4B | len 2B | payload nB] │
│ │
▼ │
4. mutex 解锁 │
│ │
▼ │
5. sem_give() ──────────────────────────► 6. sem_take() 被唤醒
│
▼
7. mutex 加锁
8. 从 ring buffer 读出消息
9. mutex 解锁(先解锁再调 handler)
│
▼
10. 二分查找 handler 表
11. on_temp(data, size, ctx)
|
两个值得注意的细节:
post() 非阻塞:消息写进 ring buffer 就立刻返回,不等 handler 执行完,handler 在消费者线程里异步执行。
先解锁再调 handler:消费者线程读完消息后立刻释放 mutex,拿数据副本去调 handler。生产者不需要等 handler 执行完才能继续 post,吞吐量更高。
3.2 ring buffer:消息的存储格式
每条消息在 buffer 里连续存三段:
1
2
3
| ┌──────────────┬──────────────┬──────────────────────┐
│ UUID (4 B) │ 长度 (2 B) │ payload(最多1KB) │
└──────────────┴──────────────┴──────────────────────┘
|
6 字节固定 header,overhead 极低。buffer 用两个指针管理:
1
2
| head —— 读指针,只有消费者线程移动
tail —— 写指针,只有生产者线程移动(受 mutex 保护)
|
下面是 buffer 在不同状态下的样子(以 16 字节 buffer 为例,每条消息占 7 字节):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| 初始(空):head == tail
[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]
↑
head/tail
写入两条消息后:
[M1][M1][M1][M1][M1][M1][M1][M2][M2][M2][M2][M2][M2][M2][ ][ ]
↑ ↑
head tail
消费者读取 M1 后:
[ ][ ][ ][ ][ ][ ][ ][M2][M2][M2][M2][M2][M2][M2][ ][ ]
↑ ↑
head tail
tail 逼近末尾,新消息放不下了(仅剩 2 格,消息需要 7 格):
[ ][ ][ ][ ][ ][ ][ ][M2][M2][M2][M2][M2][M2][M2][ ][ ]
↑ ↑
head tail
分两次 memcpy 绕回写入 M3(5 字节写到末尾,2 字节绕回开头):
[M3][M3][ ][ ][ ][ ][ ][M2][M2][M2][M2][M2][M2][M2][M3][M3]
↑ ↑
tail head
|
绕回对调用方完全透明,代码里用最多两次 memcpy 处理:
1
2
3
4
5
6
7
8
9
10
11
| static void ring_write_bytes(embedmq_t *q, const void *src, size_t n)
{
size_t end = q->buf_size - q->tail;
if (end >= n) {
memcpy(q->buf + q->tail, src, n);
} else {
memcpy(q->buf + q->tail, src, end);
memcpy(q->buf, src + end, n - end);
}
}
|
3.3 handler 表:有序插入 + 二分查找
register() 把 handler 存进一个按 UUID 排好序的数组。插入时找到正确位置,用 memmove 右移腾出空间:
1
2
3
4
5
6
7
8
9
10
| 注册前:
index [0] [1] [2]
uuid 0x1B00:on_button 0x5F00:on_wifi 0xF300:on_log
注册 "sensor.temp"(UUID=0x8A00),应插在 [1] 和 [2] 之间:
→ [2] 右移一格腾出位置
注册后:
index [0] [1] [2] [3]
uuid 0x1B00:on_button 0x5F00:on_wifi 0x8A00:on_temp 0xF300:on_log
|
注册只在启动时做一次,memmove 的开销不重要。换来的是 post() 时可以用二分查找,64 个 handler 最多比较 6 次(log₂64),比逐个遍历快得多。
3.4 FNV-1a hash:名字变数字
1
2
3
4
5
6
7
8
9
| uint32_t embedmq_uuid(const char *name)
{
uint32_t hash = 0x811C9DC5;
for (const unsigned char *p = name; *p; ++p) {
hash ^= (uint32_t)*p;
hash *= 0x01000193;
}
return hash ? hash : 1;
}
|
单次遍历,平台无关,结果确定。注册时算一次,之后 post() 只比较整数,热路径上没有字符串操作。
如果连 post() 里的 hash 都想省掉,提前缓存 UUID:
1
2
3
4
5
6
| uint32_t uuid = embedmq_uuid("sensor.temp");
while (1) {
sensor_t d = read_sensor();
embedmq_post_id(q, uuid, &d, sizeof(d));
}
|
3.5 PAL:三个平台,一套接口
src/embedmq.c 里没有一行平台相关代码,它只调用 pal/embedmq_pal.h 定义的 10 个函数:
1
2
3
| embedmq_pal_sem_create / destroy / give / take
embedmq_pal_mutex_create / destroy / lock / unlock
embedmq_pal_thread_create / join
|
三个平台各自实现这 10 个函数,编译时选一个:
| 平台 |
信号量 |
互斥锁 |
线程 |
| Linux |
sem_t (POSIX) |
pthread_mutex_t |
pthread_t |
| FreeRTOS |
SemaphoreHandle_t |
SemaphoreHandle_t |
TaskHandle_t + done 信号量 |
| 裸机 |
atomic_int(忙等) |
atomic_flag(自旋锁) |
无(手动调 poll()) |
切换平台只需一行 CMake 参数,核心代码一字不改:
1
2
| cmake -B build -DEMBEDMQ_PAL=freertos
cmake -B build -DEMBEDMQ_PAL=none
|
3.6 静态模式的内存布局
embedmq_create_static() 最有意思的地方是它只做一件事:把一整块内存切成四段,各自指向不同的数据结构。
1
2
3
4
5
6
7
8
| 传入的 buf(一块连续内存):
┌──────────────────┬─────────────────────┬─────────────────┬──────────────────┐
│ struct embedmq_s│ handler 表 │ ring buffer │ dispatch 缓冲区 │
│ (控制信息) │ max_handlers × 12B │ queue_size 字节│ max_msg_size 字节│
└──────────────────┴─────────────────────┴─────────────────┴──────────────────┘
↑ ↑ ↑ ↑
q q->handlers q->buf q->dispatch_buf
|
embedmq_mem_size() 就是把这四段的大小加起来,告诉你 buf 需要多大:
1
2
3
4
5
6
| size_t embedmq_mem_size(const embedmq_config_t *cfg) {
return sizeof(struct embedmq_s)
+ cfg->max_handlers * sizeof(embedmq_handler_entry_t)
+ cfg->queue_size
+ cfg->max_msg_size;
}
|
这个设计的好处是:一次 malloc(或一块静态数组)拿到所有内存,生命周期统一管理,不产生碎片。对于禁止动态内存分配的 MCU 项目,只需要在 BSS 段声明一个数组:
1
2
| static embedmq_config_t cfg = { .queue_size = 2048, .max_handlers = 8 };
static uint8_t mq_buf[2048 + 8*12 + 1024 + 64];
|
之后整个库的运行不会再碰堆。
四、FreeRTOS 移植:两个坑的实战记录
Linux 和裸机的后端很顺利,FreeRTOS 是真正把 PAL 抽象逼到极限的地方。
坑一:FreeRTOS task 不能 return
embedmq 的消费者循环在收到退出信号后会 break 然后 return,在 pthreads 里完全正常。但 FreeRTOS 的 task 函数绝对不能 return——一旦 return 就是未定义行为,通常直接崩溃。task 必须自己调 vTaskDelete(NULL) 结束。
解决方案是在 FreeRTOS PAL 里加一层 trampoline:
1
2
3
4
5
6
7
| static void task_trampoline(void *param)
{
embedmq_pal_thread_t *t = param;
t->fn(t->arg);
xSemaphoreGive(t->done);
vTaskDelete(NULL);
}
|
坑二:FreeRTOS 没有 pthread_join
embedmq_destroy() 必须等消费者线程真正退出后才能释放内存,否则线程还在跑,内存已经被 free,必然崩溃。pthreads 有 pthread_join 可以等。FreeRTOS 没有等价物。
解决方案是在线程句柄里放一个”done 信号量”:
1
2
3
4
5
6
| typedef struct {
TaskHandle_t handle;
SemaphoreHandle_t done;
void (*fn)(void *);
void *arg;
} embedmq_pal_thread_t;
|
destroy() 发退出信号后,等待 done 信号量:
1
2
3
4
5
| void embedmq_pal_thread_join(embedmq_pal_thread_t *t)
{
xSemaphoreTake(t->done, portMAX_DELAY);
vSemaphoreDelete(t->done);
}
|
task 在 vTaskDelete 之前 give done,join 随即返回。没有 pthread_join,用一个计数信号量模拟出了同样的语义。
模拟器上的栈大小陷阱
在 FreeRTOS POSIX 模拟器(GCC_POSIX 移植)上验证时遇到一个诡异的问题:程序启动后完全没有输出,测试 task 从未运行。
原因是 POSIX 移植里,FreeRTOS 的栈深度(depth)字段会被当作 pthread 栈大小的字节数。我把 configMINIMAL_STACK_SIZE 设成了 PTHREAD_STACK_MIN(现代 glibc 上约 16 KB),然后又乘了倍数,导致单个 task 请求超过 500 KB 的 pthread 栈。FreeRTOS heap 直接被撑爆,xTaskCreate 静默返回失败,调度器只剩 idle task 在空转。
修复方法是把深度和 pthread 栈字节数解耦:
1
2
3
|
#define configMINIMAL_STACK_SIZE \
((unsigned short)(PTHREAD_STACK_MIN / sizeof(unsigned long)))
|
教训:FreeRTOS 里”栈大小”这个数字,在 Cortex-M 上是实际栈的字(word)数,在 POSIX 移植里却同时影响 heap 分配和 pthread 栈字节数。同一个字段,完全不同的含义。
五、C++ 封装:RAII + Lambda
C API 足够用,但 C++ 封装让代码更简洁。
1
2
3
4
5
6
7
8
9
10
| #include "embedmq.hpp"
embedmq::MQ q;
q.subscribe("sensor.temp", [&](const void *data, size_t size) {
const sensor_t *s = static_cast<const sensor_t *>(data);
display.update(s->value);
});
q.publish("sensor.temp", &data, sizeof(data));
|
lambda 是怎么桥接到 C 接口的?
C 的 embedmq_register() 只接受普通函数指针,lambda 不是函数指针。C++ 封装用一个静态 trampoline 函数做桥:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
struct HandlerEntry { uint32_t uuid; Handler fn; };
entries_.push_back({ uuid, std::move(fn) });
auto *entry = &entries_.back();
embedmq_register(q_, name.c_str(), detail::trampoline, entry);
static void trampoline(const void *data, size_t size, void *ctx) {
auto *entry = static_cast<HandlerEntry *>(ctx);
entry->fn(data, size);
}
|
调用链:消费者线程 → trampoline() → lambda。entries_ 负责让 lambda 的内存一直活着,不会变成悬空指针。
六、快速上手
克隆和构建
1
2
3
4
5
6
7
8
9
10
11
12
13
| git clone https://github.com/w4ysonch/embedmq.git
cd embedmq
cmake -B build && cmake --build build
./build/example_basic
./build/example_basic_cpp
./build/test_embedmq
./build/test_embedmq_cpp
|
静态分配模式(MCU / 无堆环境)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| static embedmq_config_t cfg = {
.queue_size = 2048,
.max_msg_size = 64,
.max_handlers = 8,
};
static uint8_t mq_buf[4096];
static embedmq_t *q;
void app_init(void)
{
q = embedmq_create_static(mq_buf, sizeof(mq_buf), &cfg);
embedmq_register(q, "sensor.update", on_sensor, NULL);
}
|
裸机 superloop 模式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
embedmq_t *q = embedmq_create(&cfg);
embedmq_register(q, "tick.10ms", on_tick, NULL);
void TIM_IRQHandler(void) {
embedmq_post(q, "tick.10ms", NULL, 0);
}
void main(void) {
while (1) {
embedmq_poll(q);
__WFI();
}
}
|
七、性能数据
x86-64 Linux,Release 构建(-O2),单生产者 + 单消费者线程:
| 测试项 |
结果 |
embedmq_post() 吞吐量 |
~2,966,716 条/秒 |
embedmq_post_id() 吞吐量(UUID 预缓存) |
~3,377,094 条/秒 |
| 端到端延迟(post → handler),平均 |
~22 µs |
| 端到端延迟,最短 |
~2.6 µs |
embedmq_uuid() hash 速度 |
~131M 次/秒(约 7.6 ns/次) |
热路径上没有字符串操作、没有内存分配,只有一次整数比较(二分查找)、一次 memcpy(ring buffer 写入)、一次信号量操作。
复现方法:
1
2
| cmake -B build -DCMAKE_BUILD_TYPE=Release && cmake --build build --target benchmark
./build/benchmark
|
八、适用场景与局限性
适合用的场景:
- 嵌入式 Linux 多线程程序,模块间需要解耦通信
- FreeRTOS 多任务,不想手写队列和任务间同步
- 裸机 superloop,想统一管理事件分发
不适合的场景:
- 跨进程通信(用 Unix socket / mqueue)
- 跨网络通信(用 MQTT / ZeroMQ)
- 需要一对多广播(embedmq 每个事件名只支持一个 handler)
- handler 里有阻塞操作(会堵住消费者线程,后续消息排队等待)
几个容易踩的坑:
register() 必须在所有 post() 之前完成,且不是线程安全的- handler 运行在消费者线程,
data 指针只在调用期间有效,需要保留数据要自己拷贝
destroy() 会阻塞等消费者线程退出,调用前要确保没有线程还在 post()- 裸机 PAL 的信号量是忙等,不适合对功耗敏感的场景
结语
embedmq 的核心取舍是:用注册时的一次性开销(hash + 有序插入)换取派发时的极低延迟(整数比较 + 二分查找),以及一块连续内存管理所有内部状态带来的零碎片确定性。
适合事件种类固定、启动后不再变化的嵌入式场景。如果你的项目需要动态增删事件类型,这不是合适的工具。
项目采用 MIT 协议开源,欢迎试用和反馈。
GitHub:https://github.com/w4ysonch/embedmq